
Le SEO, ou Search Engine Optimisation et référencement en français, peut sembler complexe mais est en fait relativement simple. Dans ce guide, nous avons compilé pour vous des informations utiles que vous pouvez parcourir et à partir desquelles commencer à travailler. Avec ces éléments, vous serez sur la bonne voie pour améliorer la visibilité de votre site dans les recherches Google.
- SEO – la définition de Google
- Comment fonctionne la recherche Google ?
- Une vue simplifiée du processus
- Crawler
- Index
- Algorithme de classement
- Pages de résultats du moteur de recherche (SERPs)
- 6 bonnes raisons de se mettre au SEO
- Les SERPs de Google
- Élément #1 : SEA (Google Ad)
- Élément #2 : SEO (résultats de recherche organiques)
- Élément #3 : Recherche universelle
- Autres fonctionnalités des SERPs
- Élément #4 : Extrait en vedette ou Featured Snippet
- Élément #5 : Knowledge-Graph
- Élément 6 : Google Shopping
- Domaine, sous-domaine, hôte et URL
- Facteurs de classement Google
- Google est votre source pour un référencement réussi
- Aidez Google à trouver votre site Web
- Aidez Google à comprendre votre site Web
- Aidez le visiteur à utiliser le site Web
- Principes de base des directives générales d'évaluation de la qualité des recherches
- Évitez les méthodes suivantes
- Que couvre les directives générales d'évaluation de la qualité des recherches ?
- Glossaire SEO des termes
- Lectures complémentaires
SEO – la définition de Google
Qu’est-ce que le SEO ? Commençons par regarder la définition du référencement de Google ? « En vous assurant que les moteurs de recherche peuvent trouver et comprendre automatiquement votre contenu, vous améliorez la visibilité de votre site pour les recherches pertinentes. C’est ce qu’on appelle le SEO ».
Comment fonctionne la recherche Google ?
Google est le moteur de recherche le plus utilisé en Europe. Au Royaume-Uni, il a une part de marché d’environ 90 % et, par conséquent, Google a l’avantage naturel de définir les méthodes SEO autorisées et celles qui ne le sont pas.
Lorsque vous recherchez un mot-clé ou un terme sur Google, les résultats s’affichent presque instantanément, mais comment Google trouve-t-il les sites Web pertinents et comment classe-t-il les résultats ?
Une vue simplifiée du processus

Crawler
Le Googlebot parcourt (recherche parmi) des milliards de pages Web chaque jour à la recherche de contenu nouveau et mis à jour. Il ajoute certaines de ces pages à son index.
Index
Pour qu’un site Web soit trouvé par pendant la recherche, Google doit l’avoir dans son index. Google doit également ajouter des informations pertinentes sur le site à son index.
Algorithme de classement
Lorsqu’une recherche est lancée, Google regarde les résultats en fonction d’un algorithme de classement.
Pages de résultats du moteur de recherche (SERPs)
Google utilise environ 200 signaux de classement pour trouver le meilleur résultat dans l’index pour la requête donnée. Tous les résultats correspondants formeront la liste des résultats de recherche – les SERPs (Search Engine Results Pages).
Dans nos pages de ressources (Demandez à SISTRIX, Tutoriels, Blog, etc.), vous trouverez un grand nombre d’articles sur l’exploration, l’indexation et l’algorithme de classement de Google.
6 bonnes raisons de se mettre au SEO
Le SEO est gratuit. Par rapport à Google Adwords qui peut également apparaître dans les résultats de recherche, le fait de figurer dans les résultats de recherche « organiques » ne coûte rien.
Le SEO vous apporte du trafic pertinent. Si vous interprétez correctement l’intention de recherche de l’utilisateur et présentez un contenu qui y correspond, les résultats de la recherche peuvent vous fournir un trafic de qualité.
Le SEO est plus pertinent que le SEA. D’après les recherches que nous avons menées chez SISTRIX, plus de 93% des clics vont aux résultats de recherche organiques et moins de 7% à la publicité sur les moteurs de recherche.
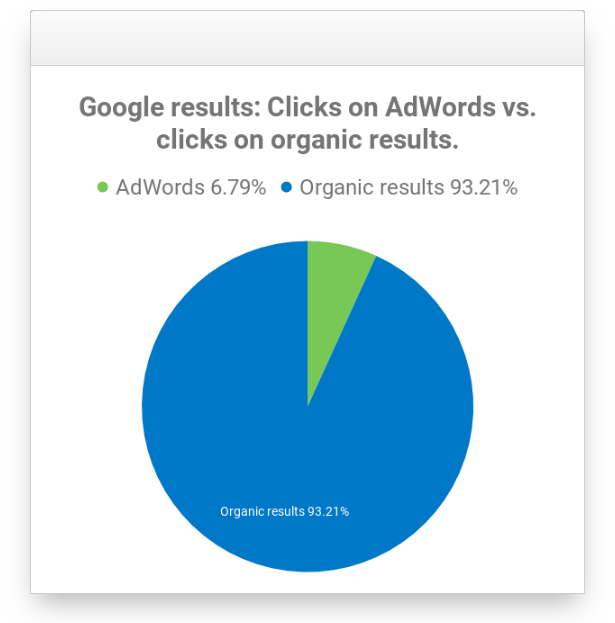
Le SEO peut réduire la concurrence. Les positions de classement sont limitées (généralement 10), donc avec un bon référencement, on peut déplacer la concurrence en obtenant une présence plus élevée dans les SERPs de Google pour son site.
Le SEO peut renforcer l’image. La notoriété de la marque pour les groupes cibles peut être améliorée grâce à une visibilité accrue dans les résultats des moteurs de recherche.
Les SERPs de Google
Les SERPs sont présentées de différentes manières en fonction de la taille de l’écran. Un résultat de recherche typique sur desktop dans Google (une SERP) est généralement formé des éléments suivants. En haut de la page, vous trouverez souvent les Google Ads (dans le cadre jaune ci-dessous). Celles-ci n’apparaissent pas pour tous les résultats de recherche. Sous ces annonces commencent les résultats de recherche organiques jugés importants (dans le cadre vert ci-dessous).
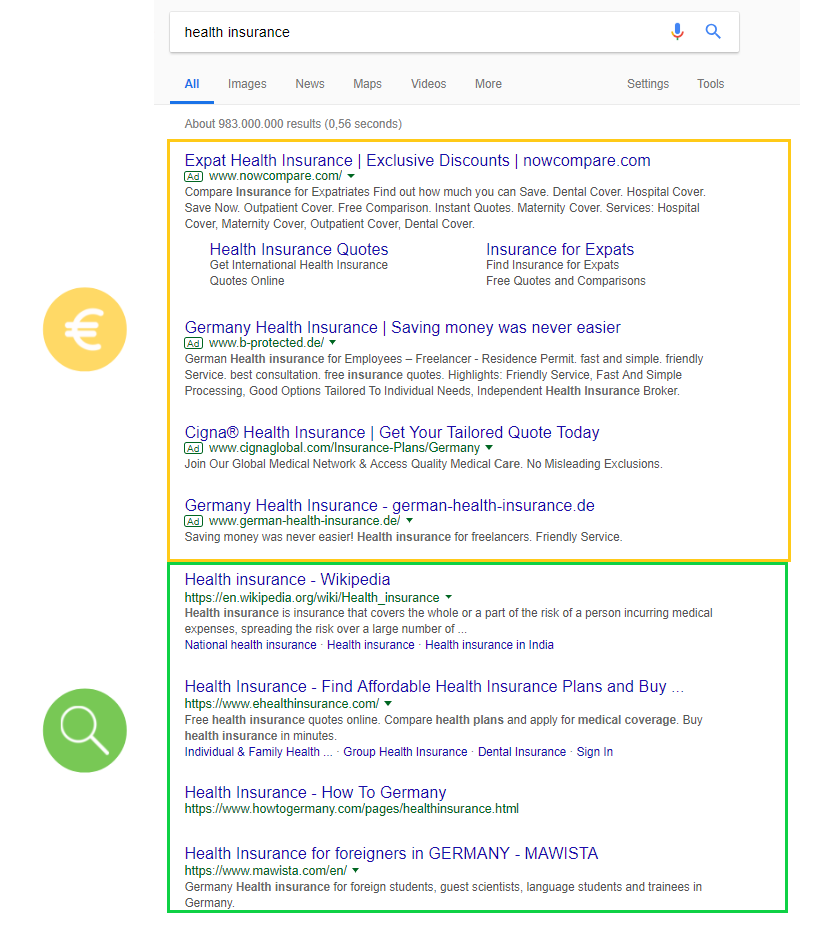
Dans la version mobile, vous trouverez également les modules de recherche universels présentés avec les éléments suivants :
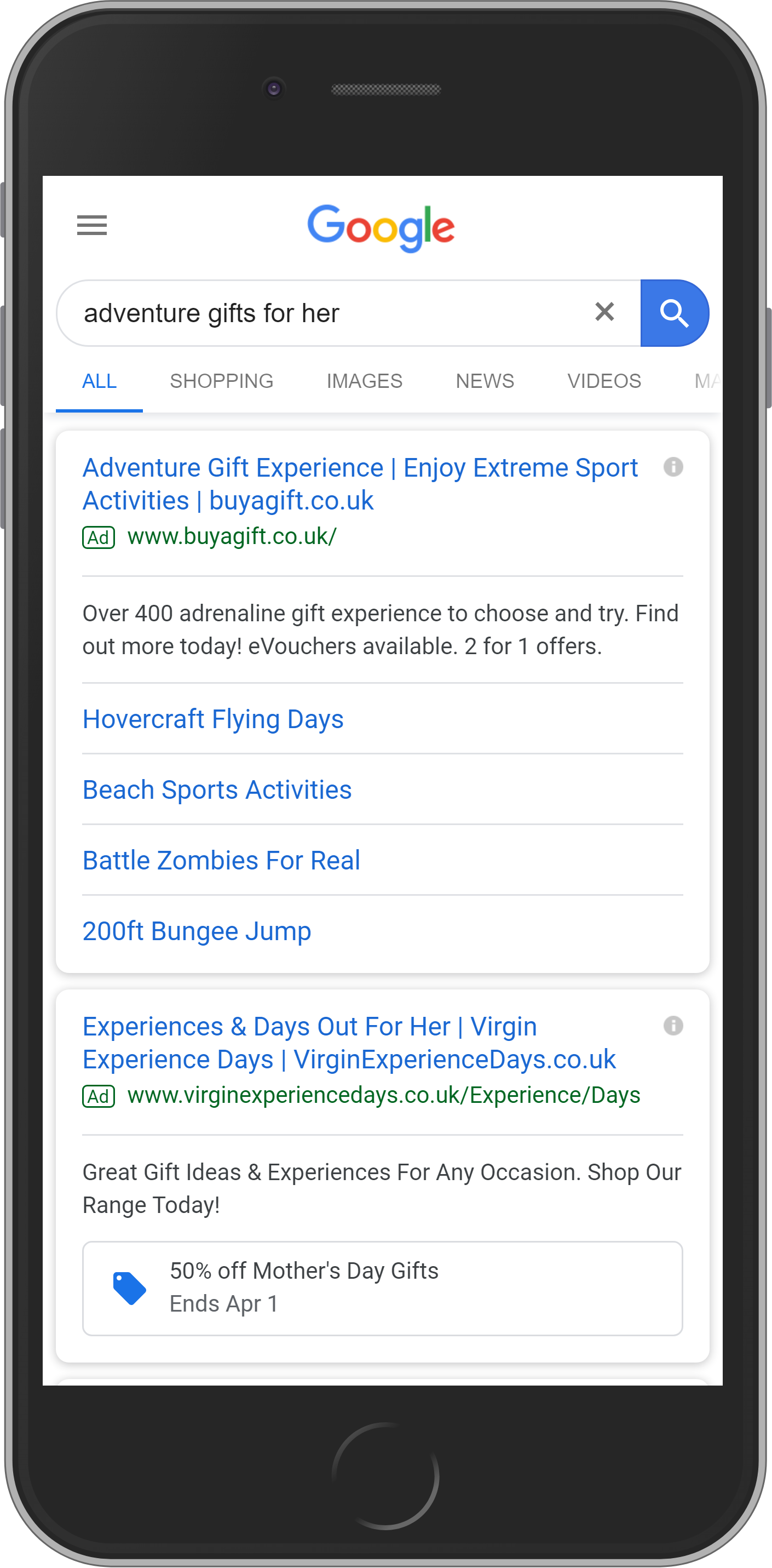
Élément #1 : SEA (Google Ad)
La plupart des SERPs incluent des annonces Google au-dessus des résultats de recherche organiques et jusqu’à trois annonces en dessous également. Toutes les annonces sont signalées par « Sponsorisé » à côté de l’URL.
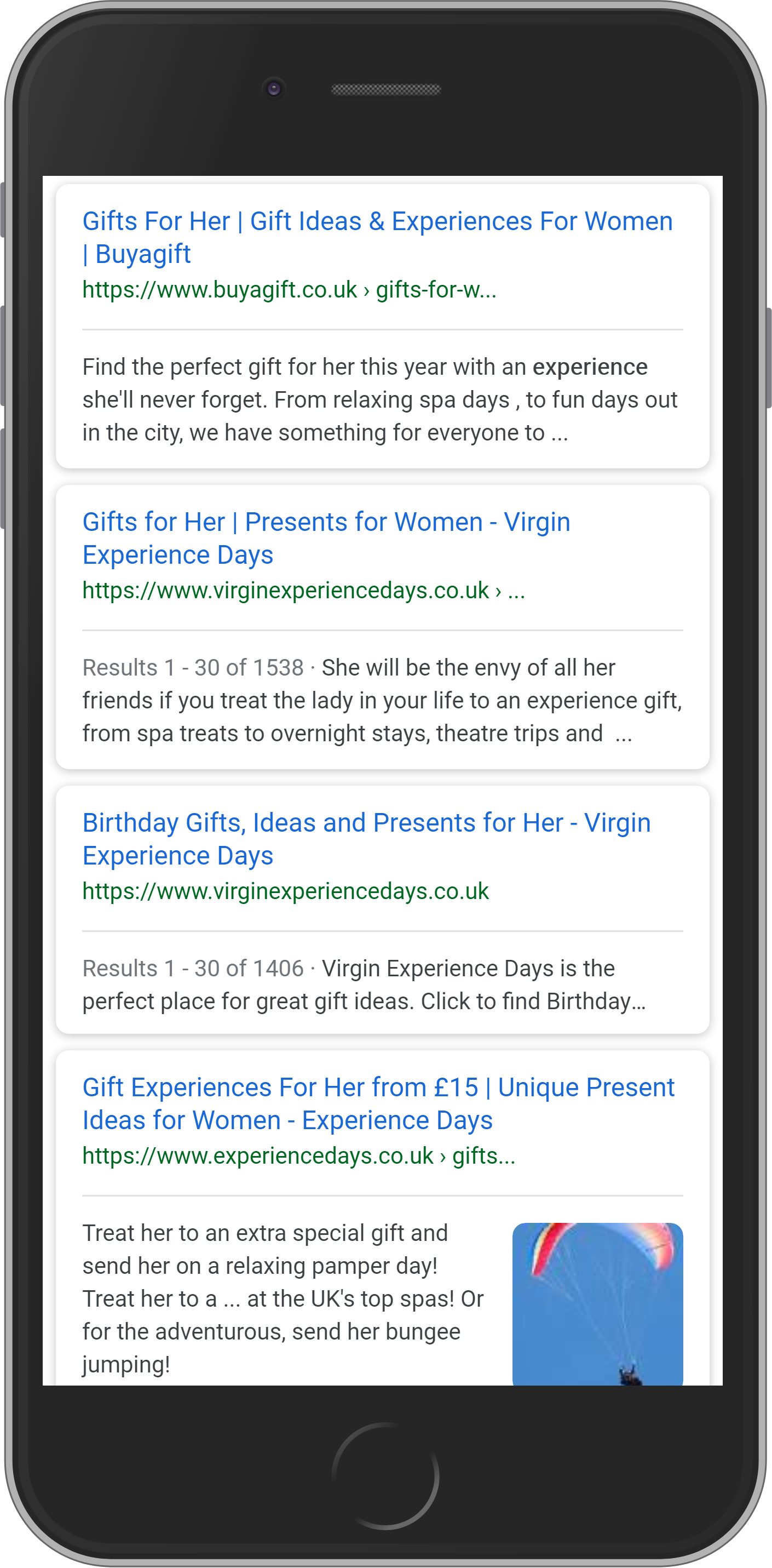
Élément #2 : SEO (résultats de recherche organiques)
Vous trouverez les résultats de recherche organiques (résultats SEO) entre les deux sections de recherche payante (Google Ad).
En règle générale, vous pouvez vous attendre à 10 résultats de recherche organiques dans cette section et ils comptent comme des résultats de SEO.
Élément #3 : Recherche universelle
Le troisième élément de recherche important est une boîte de recherche universelle. Les résultats ici sont tirés d’autres produits de recherche Google tels que News, Image et Maps et sont automatiquement intégrés dans la page.
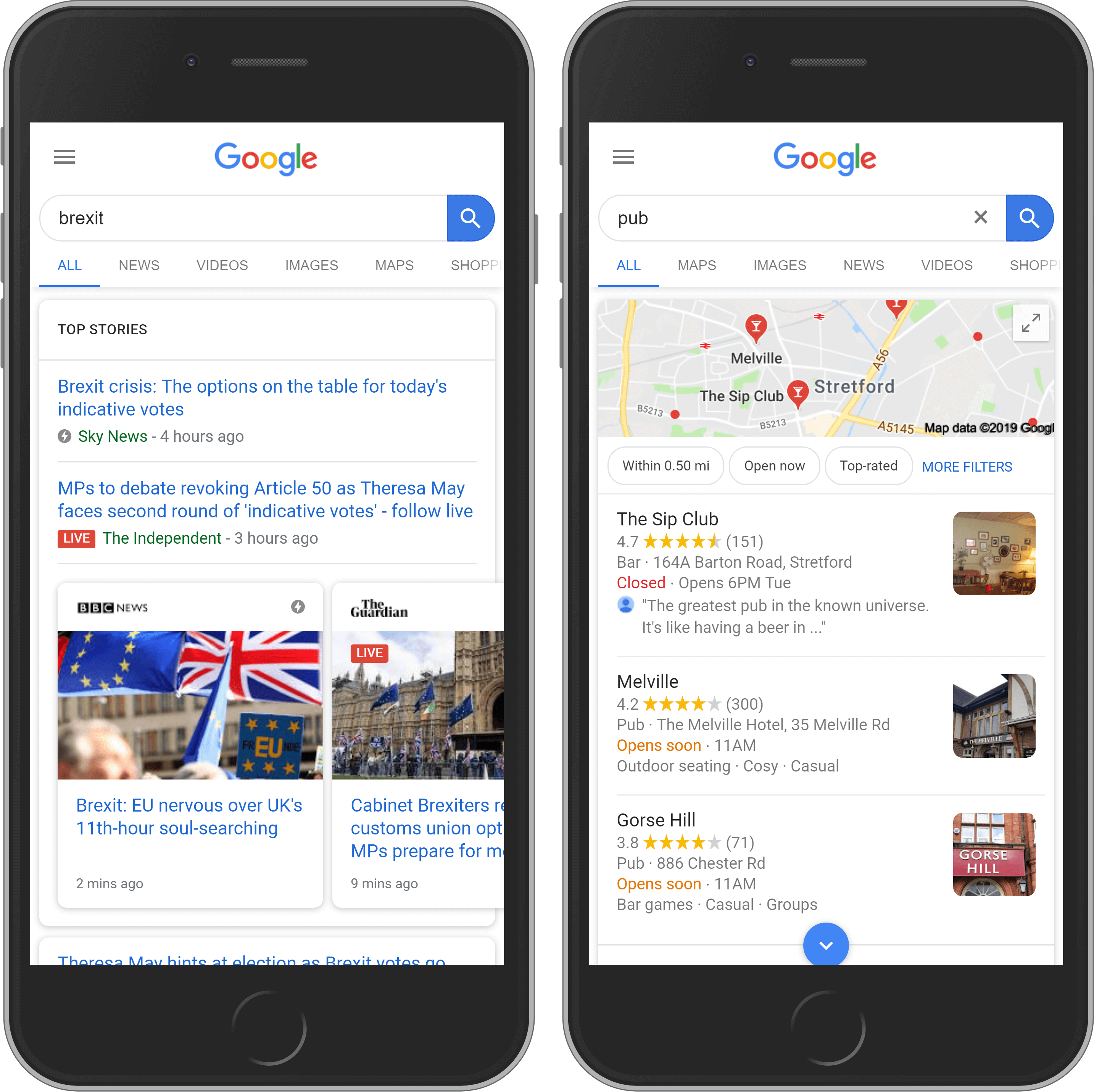
Autres fonctionnalités des SERPs
En plus des trois éléments décrits ci-dessus, il existe un certain nombre de résultats SERP supplémentaires qui, selon le type de recherche, peuvent apparaître dans les résultats. Voici quelques exemples.
Élément #4 : Extrait en vedette ou Featured Snippet
Un extrait en vedette est un extrait de SERP étendu. Les informations supplémentaires peuvent apparaître sous forme de textes, de vidéos, de listes ou de tableaux.
L’extrait en vedette se trouvera toujours à la « position zéro », c’est-à-dire au-dessus des résultats de recherche naturels.
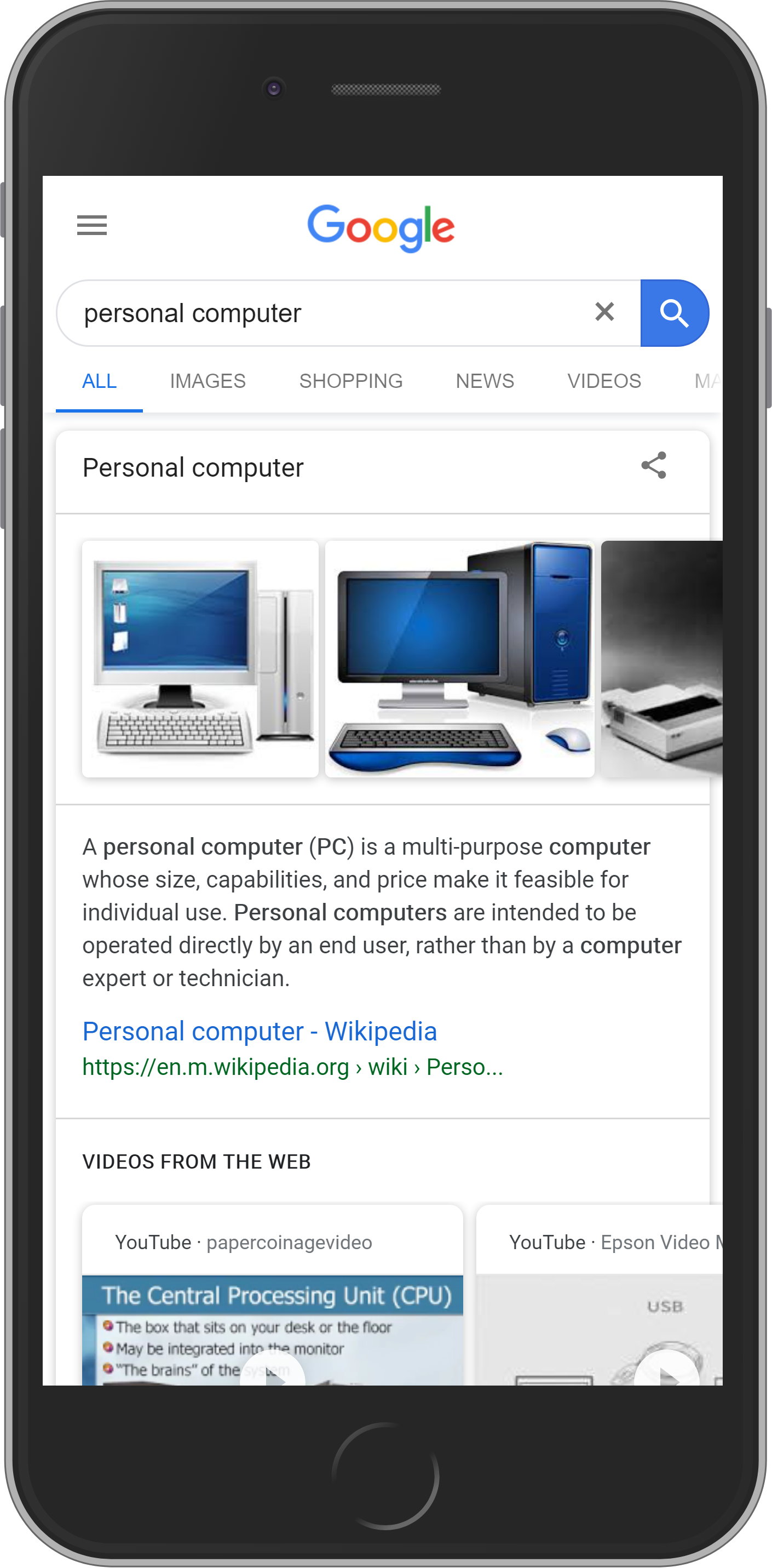
Élément #5 : Knowledge-Graph
Le graphe de connaissances apparaîtra à droite des résultats de la recherche sur la version desktop et en ligne comme premier résultat sur mobile. Il contient une sélection d’informations sur des lieux, des personnes et des sujets communs.
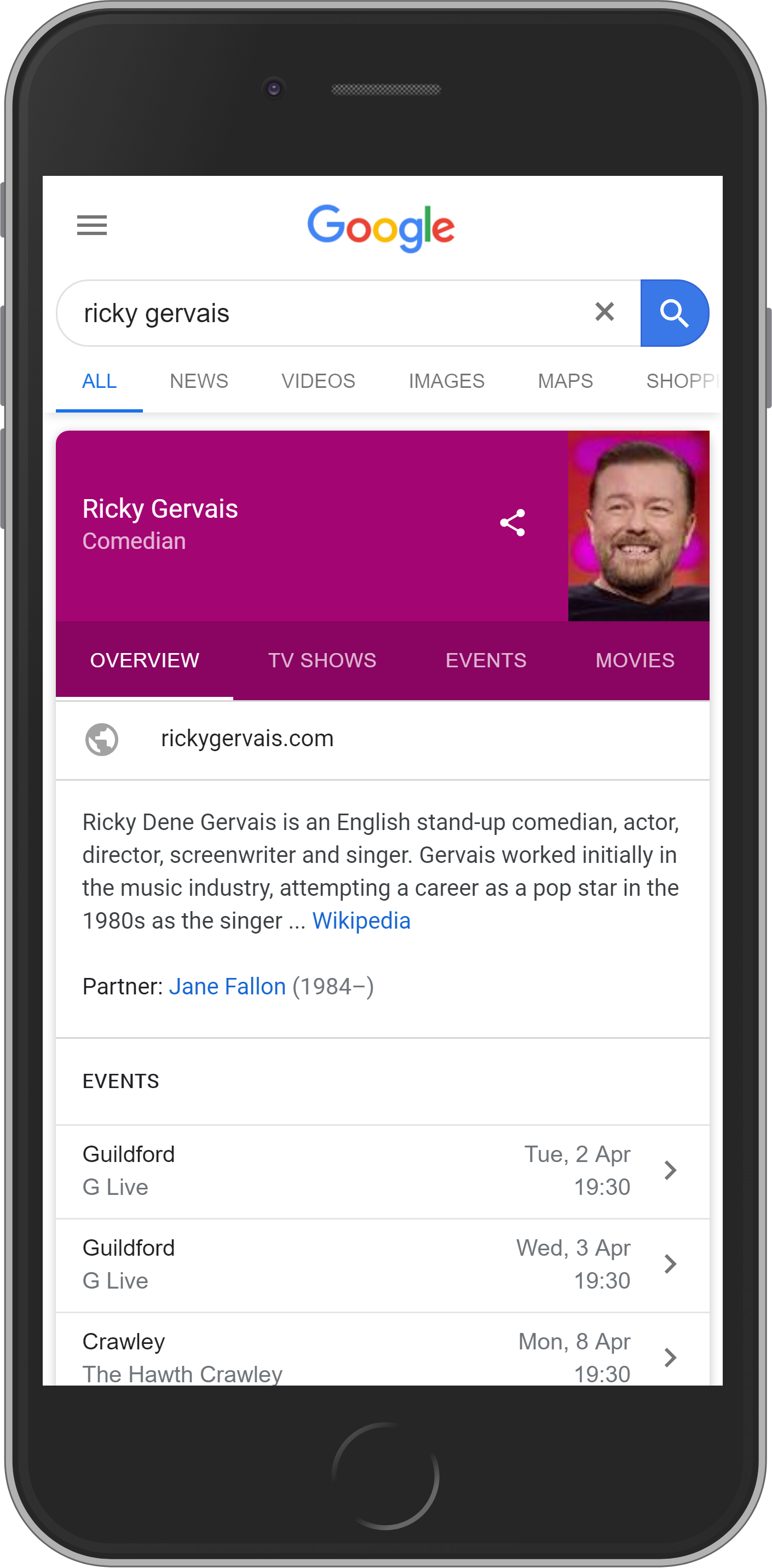
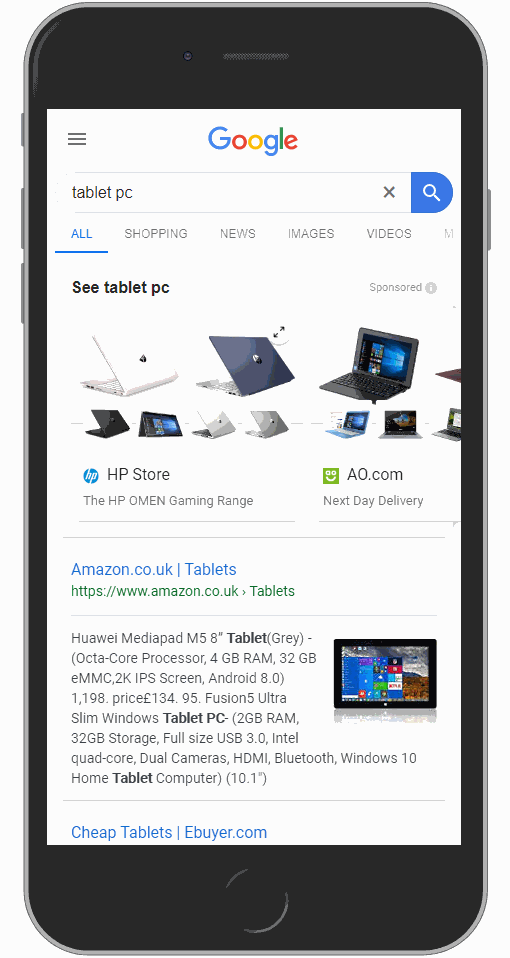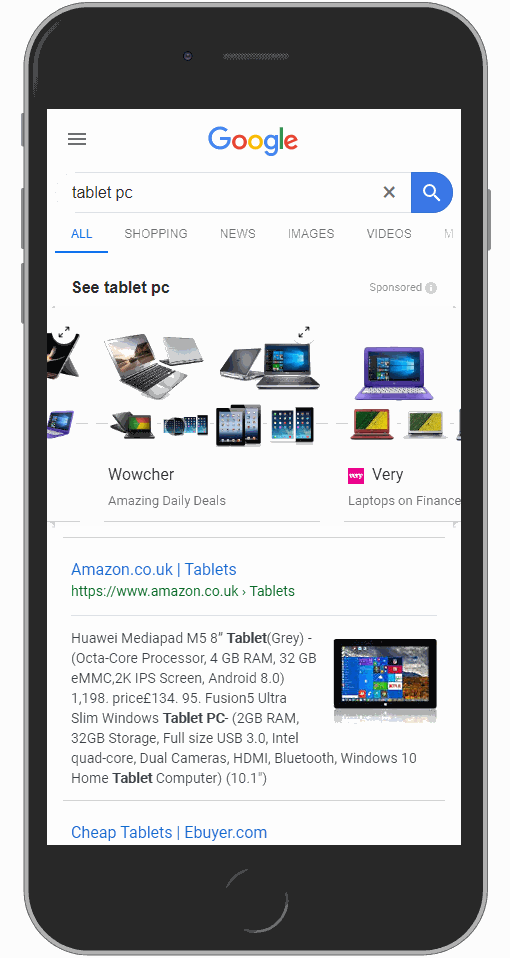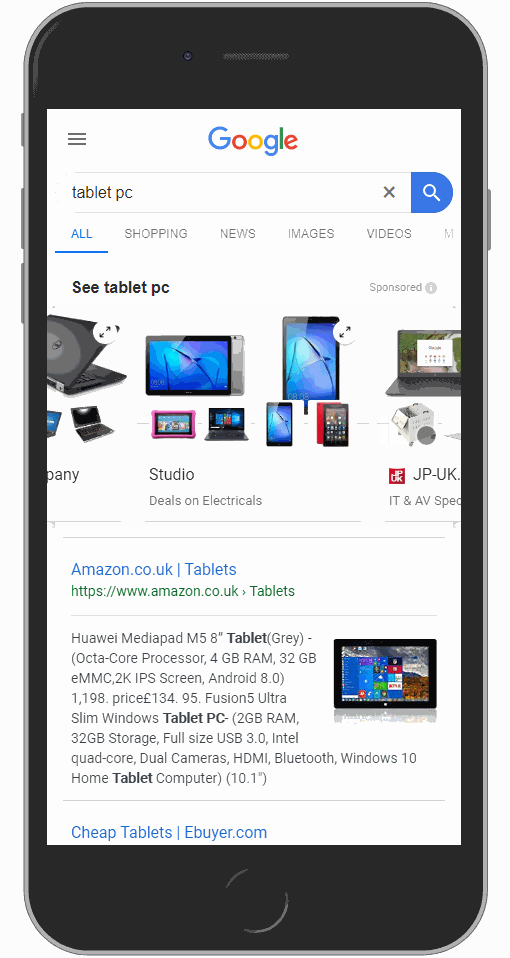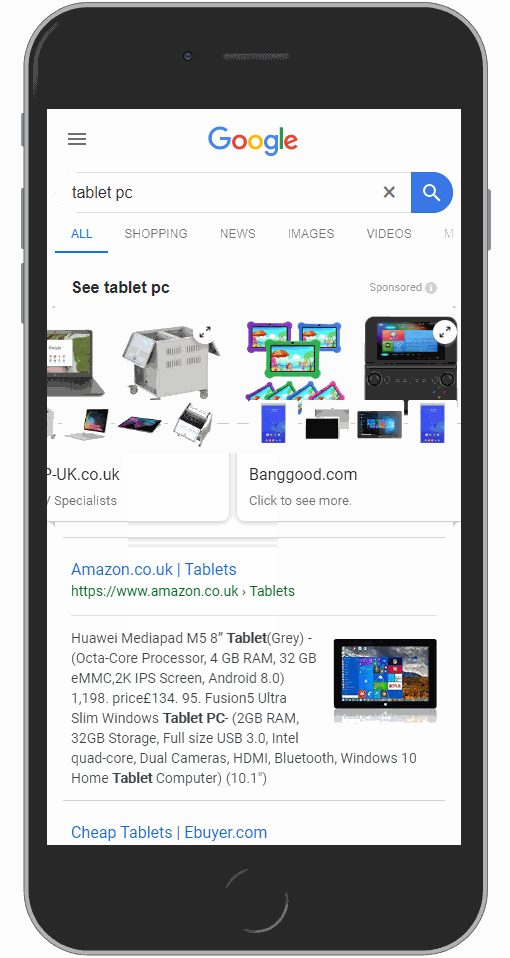
Élément 6 : Google Shopping
Un élément Google Shopping se trouve souvent à droite des éléments de recherche (recherche sur ordinateur) mais peut également apparaître au-dessus des SERPs. Il apparaît généralement au format carrousel ou mosaïque.
Domaine, sous-domaine, hôte et URL
Une adresse Web est formée de différents composants.
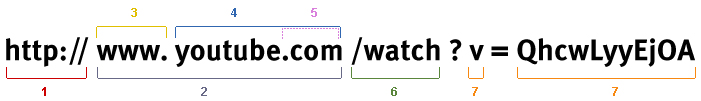
- Le protocole utilisé. Dans la plupart des cas aujourd’hui, il s’agit d’un protocole HTTPS – Hypertext Transfer Protocol (Secure) mais FTP et d’autres protocoles sont parfois pris en charge par les navigateurs.
- Le nom d’hôte : www.youtube.com qui est formé de :
- Le sous-domaine : www. (ou blog. , actualités. , support. , …)
- Un nom de domaine
- Le domaine de premier niveau (TLD) Dans notre exemple il s’agit du .com
- Le chemin : /watch. Il s’agit souvent d’un simple sous-répertoire sur le serveur Web (mais ce n’est pas obligatoire).
- Paramètre et valeur : les paramètres sont spécifiés après le « ? ». Dans ce cas, le paramètre est « v » et la valeur est « QhcwLyyEjOA ». Ceux-ci peuvent être interprétés par le serveur Web pour un traitement ultérieur.
Il est généralement entendu que lorsque quelqu’un parle d’une URL, il fait référence à un chemin dans un répertoire (https://www.reddit.com/r/Unexpected/ par exemple) ou à un fichier (C:\Users\Steve Paine \Images\Frag-SISTRIX_URL-Aufbau.jpg )
Plus d’informations sur les différences entre un domaine, un chemin et une URL
Facteurs de classement Google
Lorsque nous parlons de la recherche Google et de l’algorithme de recherche, certains facteurs influencent la manière dont les résultats sont positionnés et affichés dans les résultats de recherche.
Trouver une source de données fiable pour les facteurs de classement Google n’est pas facile car il y a beaucoup d’informations incorrectes qui circulent.
Le meilleur conseil est d’utiliser Google comme source d’information et à cette fin, nous vous recommandons le document suivant :
Guide de démarrage de l’optimisation pour les moteurs de recherche (SEO)
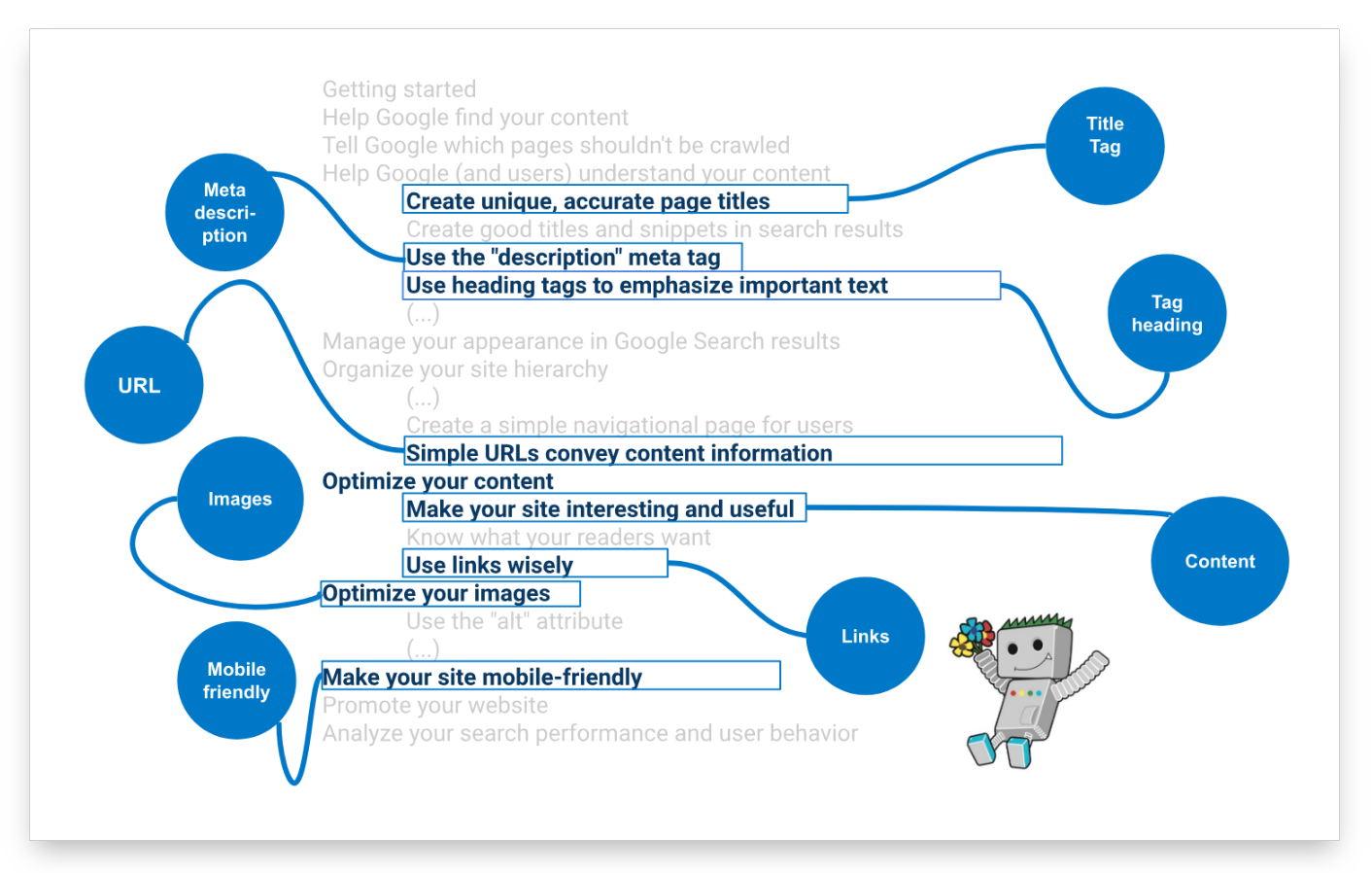
Parmi beaucoup d’autres choses, vous trouverez des informations plus détaillées sur les facteurs de classement les plus importants.
Google est votre source pour un référencement réussi
Pour un SEO réussi et durable, nous recommandons, en plus du guide ci-dessus, d’utiliser les ressources suivantes pour obtenir des conseils utiles et apprendre comment les résultats de recherche sont créés.
Jetons un coup d’œil maintenant à certains des conseils pour les webmasters. Quels critères Google énumère-t-il ?
Aidez Google à trouver votre site Web
- Assurez-vous que toutes vos pages sont visibles via des liens internes.
- Utilisez un sitemap
- Gardez le nombre de liens internes au minimum
- Utilisez le HTTP-Header If-Modified-Since
- Gérez le Crawling-Budget (robots.txt)
- Soumettez le site Web à Google (Search console)
Aidez Google à comprendre votre site Web
- Créez un site Web utile et informatif
- Comprenez l’intention de recherche de votre public cible et créez un contenu qui va en ce sens
- Utilisez une hiérarchie de site claire
- Assurez-vous que votre CMS n’empêche pas Google d’accéder au contenu
- Assurez-vous que les autres éléments, tels que les données CSS et Javascript, sont accessibles par Google
- Réduisez la visibilité des identifiants de session et des paramètres d’URL pour les robots de recherche
- Empêchez les crawlers de suivre les liens publicitaires à l’aide de robots.txt ou rel= »nofollow »
Aidez le visiteur à utiliser le site Web
- Tous les liens doivent être valides et pointer vers des pages en direct
- Optimisez le temps de chargement du site Web
- Rendez le site Web compatible avec différentes tailles d’écran
- Rendez le site Web compatible avec différents navigateurs
- Créez un site Web sans barrière (tailles de texte, couleurs, positionnement, par exemple)
Principes de base des directives générales d’évaluation de la qualité des recherches
- Créez un site Web pour les utilisateurs, pas pour les moteurs de recherche
- Ne créez pas différentes expériences utilisateur/crawler via le cloaking
- Évitez d’utiliser des méthodes d’amélioration du classement manipulatrices
- Créez une expérience de site Web unique
Évitez les méthodes suivantes
- Programmes d’échange de liens
- Cloaking
- Bridging ou Doorway pages
- Liens cachés
- Contenu copié
- (…)
Que couvre les directives générales d’évaluation de la qualité des recherches ?
L’essentiel des directives générales d’évaluation de la qualité des recherches concerne le test manuel des nouveaux algorithmes des moteurs de recherche par des tiers sous contrat.
Cependant, grâce aux directives, longues de plus de 160 pages, il est possible d’avoir une idée de ce que Google veut voir en termes de qualité.
Le document complet, au format PDF, est disponible ici et sa lecture est fortement recommandée.
Glossaire SEO des termes
Vous trouverez de nombreux termes spécialisés utilisés dans le monde du SEO. Pour vous aider à les comprendre, nous avons créé une liste des mots les plus importants accompagnés de leurs définitions.
Attribut Alt. Ceci est lié à l’étiquetage alternatif d’une image. Google est capable de comprendre le contenu de l’image grâce à l’utilisation d’une description courte et précise qui contient des mots-clés importants.
Texte d’ancre. La description d’un lien est connue sous le nom de texte d’ancre. En pratique, il s’agit simplement de la partie surlignée et cliquable du lien texte.
Liens retour. Le terme de backlinks ou de liens retour désignent les liens qui connectent un domaine à un autre domaine externe. Les utilisateurs peuvent cliquer sur ces liens pour accéder au contenu externe. Ce sont toujours des facteurs de classement importants pour Google.
Taux de rebond. Cette valeur, également connue sous le nom de bounce-rate en anglais, indique la fréquence à laquelle un utilisateur quitte un site Web sans avoir consulté au moins une page supplémentaire sur le site.
Balise canonique. Avec la balise canonique (ou Canonical Tag en anglais), vous pouvez définir l’URL d’origine. S’il existe des pages sur un site Web avec le même contenu, Google peut utiliser la balise canonique pour comprendre qu’une des pages est la plus importante et éviter ainsi l’indexation du contenu en double. Astuce : Il n’y a que quelques utilisations légitimes pour une balise canonique où elle sert principalement de « pansement » pour d’autres problèmes qui ne peuvent pas être résolus.
Conversion. Un terme utilisé dans les pratiques de marketing en ligne où une action finale se produit après qu’un utilisateur a atterri sur une page. Par exemple, un achat, un téléchargement ou un abonnement.
Contenu dupliqué. Lorsque le même contenu se trouve sur plusieurs URLs, on parle de contenu dupliqué. Il est important d’éviter cela et de s’assurer que le contenu n’est accessible que via une seule URL. Si ce n’est pas le cas, Google ne sait pas quelle URL doit être classée pour ce contenu et quels signaux de classement positifs doivent être attribués à ces URLs.
Crawler. Logiciel automatisé qui visualise le contenu du site, suit les liens, lit le sitemap et enregistre la structure et le contenu au fur et à mesure.
Featured Snippet. Un extrait en vedette est une information qui peut répondre directement à la requête des utilisateurs. Un extrait de code est formé à partir de la balise de titre, de l’URL et de la réponse à la requête. Il peut prendre la forme d’un texte, d’une vidéo, d’un tableau ou d’une liste.
Attribut de liens. Avec un « Follow-attribute », il est possible de dire aux robots des moteurs de recherche de suivre les liens. Les liens externes qui sont suivis transmettent ce qu’on appelle du « link jus », un signal important pour Google, au site lié.
Google PageRank. Le PageRank est une valeur attribuée à un site Web via un algorithme créé par les fondateurs de Google, Larry Page et Sergei Brin. La valeur de 1 à 10 (et qui n’est plus accessible au public) est une valeur de la réputation d’un site basée sur le nombre et la valeur des liens entrants. Il continue d’être utilisé dans le cadre de l’algorithme de Google.
Googlebot. Nom commun du robot d’exploration Google. Le Googlebot parcourt continuellement Internet à la recherche de sites Web.
Code d’état HTTP. Un HTTP status code est envoyé par chaque serveur Web en réponse à chaque requête HTTP ou HTTPS. Les valeurs entrent dans des plages avec des significations différentes. Par exemple 200 pour indiquer une demande de contenu réussie, 3xx, 4xx ou 5xx ainsi que bien d’autres.
Attribut hreflang. En utilisant l’attribut hreflang, vous pouvez vous assurer que Google comprend la cible géographique du site Web et fournit la langue correcte ou l’URL régionale à l’utilisateur.
Index. Chaque page Web connue de Google est ajoutée à son index. L’entrée d’index décrit le contenu et l’emplacement (URL).
L’indexation. Il s’agit du processus qui consiste à récupérer une page, à la lire et à l’ajouter à l’index.
JavaScript. Javascript est un langage informatique qui permet une variété d’options de conception et de mise en œuvre telles que des carrousels d’images et l’interactivité des pages qui peuvent être incluses dans une page Web.
Meta Description. La balise « meta description » résume les sujets abordés sur la page pour Google et les autres moteurs de recherche. Le titre d’une page peut comporter quelques mots ou une expression. La balise « meta description » d’une page, quant à elle, peut contenir une ou deux phrases ou même un court paragraphe. Google Search Console fournit un rapport d’améliorations HTML pratique qui inclut des informations sur les balises « meta description » trop courtes, trop longues ou trop souvent dupliquées. Les mêmes informations sont également disponibles pour les balises <title>. Comme la balise <title>, la balise meta description est également placée à l’intérieur de l’élément <head> du document HTML.
Meta-Tags. Les balises Meta permettent aux webmasters de fournir des informations sur leurs sites Web aux moteurs de recherche. Les balises Meta peuvent être utilisées pour fournir des informations à un large éventail de clients. Chaque système traite uniquement les balises Meta connues et ignore les balises inconnues. Les balises Meta sont placées dans la section <head> du document HTML.
Adapté aux mobiles ou Mobile-Friendly. Il s’agit de la convivialité d’une page sur un écran mobile.
Balise d’attribut nofollow. La balise nofollow indique au moteur de recherche qu’il ne doit pas suivre un ou plusieurs liens sur une page. Ainsi, la page liée n’est pas explorée. De plus, la valeur de l’attribut nofollow ne propage pas le « linkjuice » du PageRank à la page de destination liée, de sorte que l’attribut nofollow ne doit jamais être utilisé pour les liens internes.
Valeur noindex. La valeur des meta-robots « noindex » indique à un moteur de recherche de ne pas inclure la page correspondante dans l’index Google. L’indexation d’une page (URL) peut ainsi être activement contrôlée par le webmaster.
Robots.txt Un fichier robots.txt est un fichier à la racine du site Web qui spécifie les parties du site Web auxquelles les robots des moteurs de recherche ne doivent pas accéder. Le fichier utilise le Protocole d’exclusion des robots, un protocole simple avec quelques instructions qui sont communiquées dans le fichier texte. Ce fichier spécifie l’accessibilité du site pour des sections individuelles et pour différents types de robots d’exploration Web, tels que : les robots d’exploration pour mobiles, par opposition aux robots d’exploration desktop.
SERP. La SERP ou Search Engine Result Page, répertorie les résultats de recherche (également appelés hits) d’une requête de recherche (mot-clé) sur un moteur de recherche (Google). Il y a généralement 10 résultats naturels ou organiques et 3 à 5 annonces Google payantes.
Fonctionnalités SERP. C’est le nom que nous donnons, dans la Toolbox SISTRIX, aux différentes formes d’extraits qui peuvent apparaître dans les résultats de recherche Google. Exemples : images, Adwords, boîtes à actualités, graphes de connaissances et cartes.
SEO. L’optimisation pour les moteurs de recherche décrit toutes les mesures qui peuvent être prises pour augmenter la rentabilité d’un site Web en ciblant les visiteurs via les résultats de recherche organiques.
TLD. Domaine de premier niveau (Top Level Domain en anglais). Partie du nom de domaine qu’on voit à la fin. Des exemples courants sont .com .org. et les domaines nationaux de premier niveau tels que .fr
Titre-Tag. La balise de titre représente le titre d’une URL et s’affiche, par exemple, dans les onglets du navigateur Web. Dans la plupart des cas, Google affiche également la balise de titre comme en-tête d’un résultat de recherche (SERP). Le contenu de l’élément de titre d’une page (URL) est un facteur de classement important et doit donc toujours être défini.
Redirection 301. Une redirection 301 est un code d’état HTTP 301 – Déplacé de façon permanente. Cela signifie que le contenu d’une URL a été définitivement déplacé et peut maintenant être trouvé sous une autre (nouvelle) URL.
Redirection 302. Une redirection 302 est un code d’état HTTP 302 – Déplacé temporairement. Cela signifie que le contenu d’une URL a été déplacé pendant un temps limité et peut maintenant être trouvé sous une autre (nouvelle) URL.
Lectures complémentaires
- Comment fonctionne la recherche Google – Ce que dit Google à propos de la recherche
- Le Blog SISTRIX – études de cas et actualités