
La plupart des analyses et des fonctions de SISTRIX sont déjà basées sur les données SERP de la base de données étendue. Ces données seront désormais également utilisées par défaut pour l’historique des mots-clés et les URL de classement.
Le nombre de classements d’une page dans le Top-10 et le Top-100 de Google, ainsi que le nombre d’URL différentes qui se classent, sont des informations intéressantes pour un référenceur, notamment pour les analyses chronologiques.
Alors qu’auparavant l’affichage de ces données concernait un million de mots-clés, le nouveau paramètre par défaut est désormais basé sur des données approfondies.
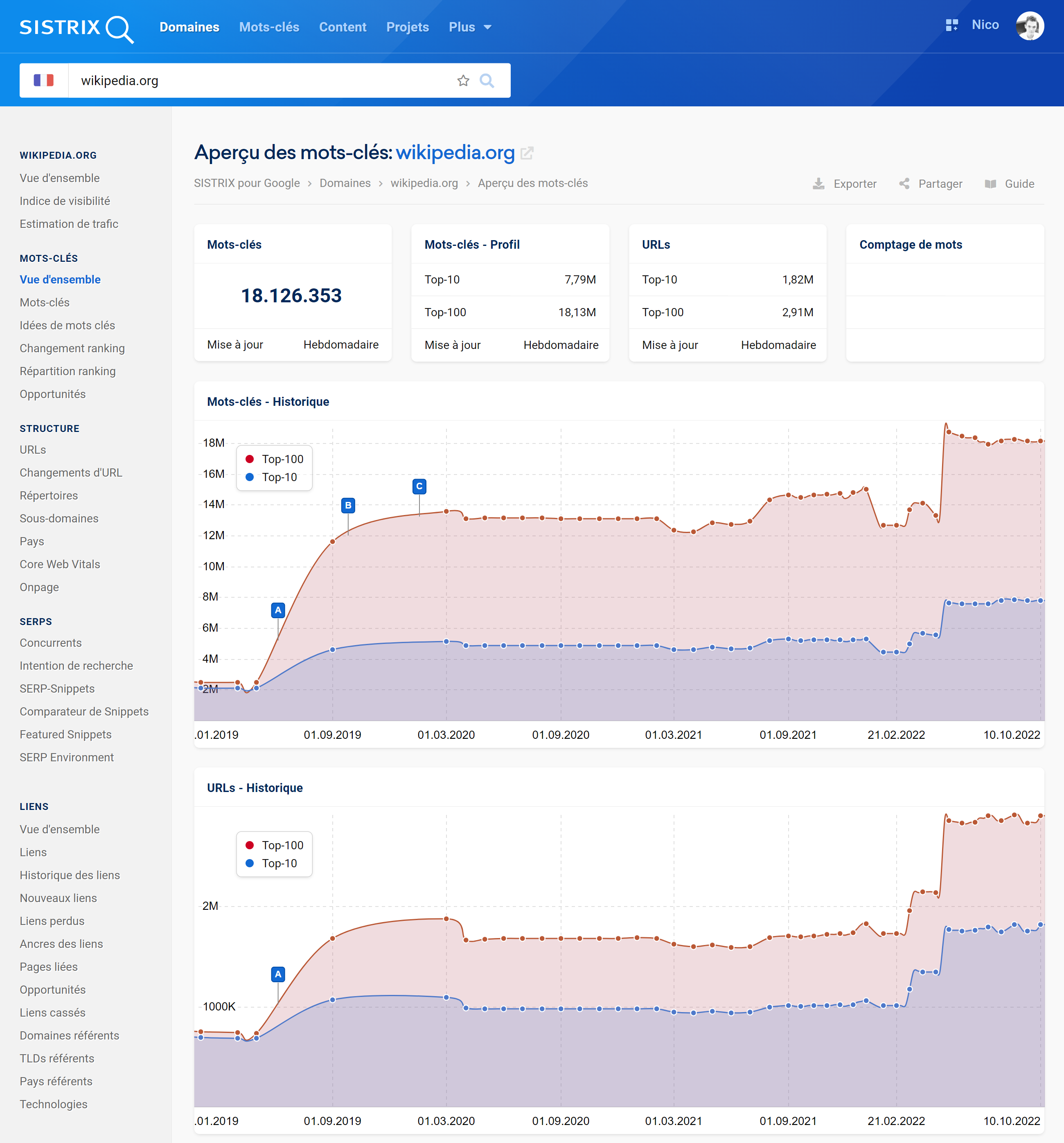
À cette fin, nous conservons un aperçu hebdomadaire des données de classement pour chacun des douze derniers mois, tandis que, pour les périodes antérieures, nous les réduisons à un point de données par mois.
Comme toujours avec SISTRIX, ces données peuvent être consultées et analysées rétrospectivement dans le temps, non seulement pour des domaines entiers, mais aussi pour des sous-domaines, des répertoires ou des URL individuelles.
Les données standard pour les smartphones et les ordinateurs de bureau restent toujours disponibles
Bien sûr, il est toujours possible d’utiliser des développements basés sur les données standard (un million de mots-clés) pour les SERP des smartphones et des ordinateurs de bureau. Pour passer d’une source de données à l’autre, il suffit d’utiliser les options du graphique correspondant à tout moment.
Quelle base de données est la mieux adaptée à mon analyse ?
Comme c’est souvent le cas en matière d’optimisation des moteurs de recherche, il n’existe malheureusement pas de réponse unique à cette question. Voici les principaux avantages et inconvénients de ces deux types de bases de données.
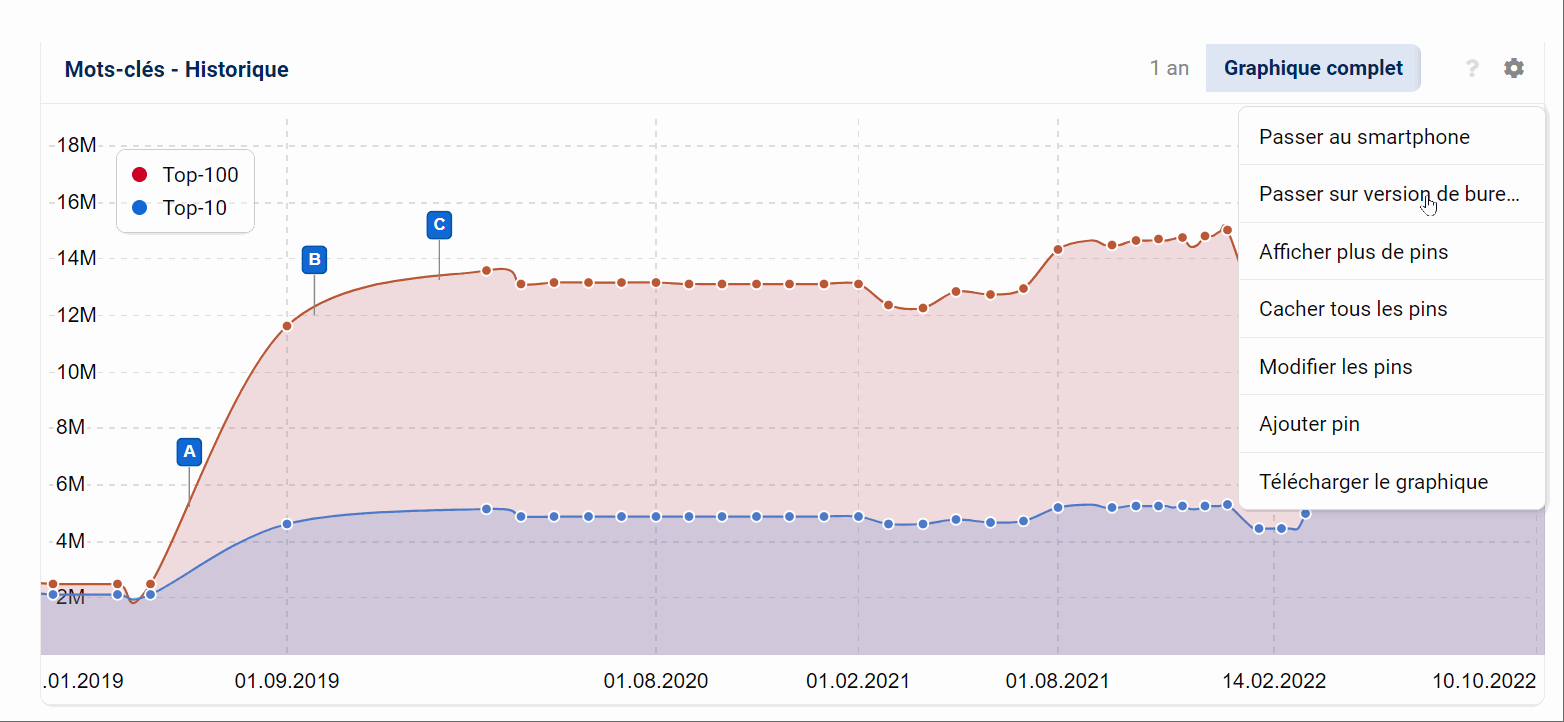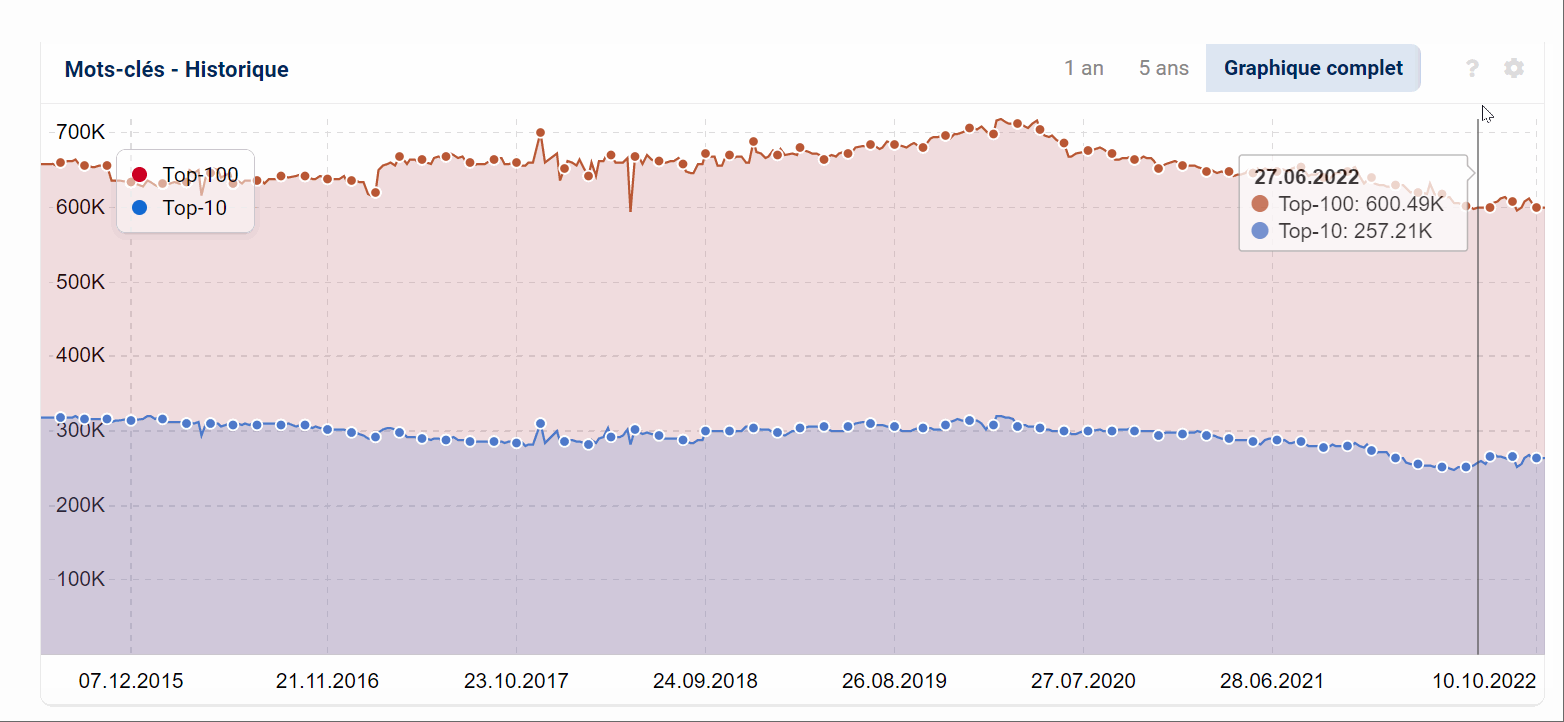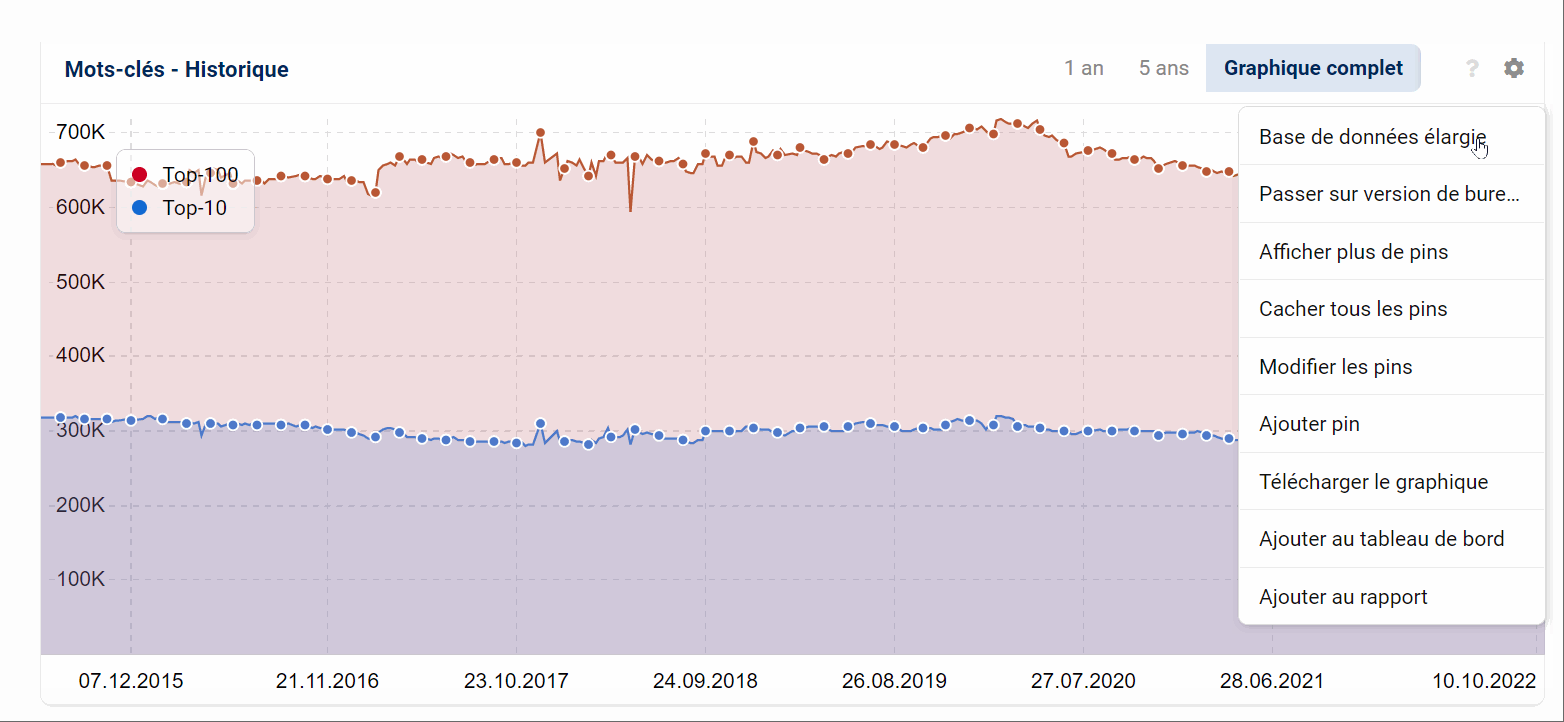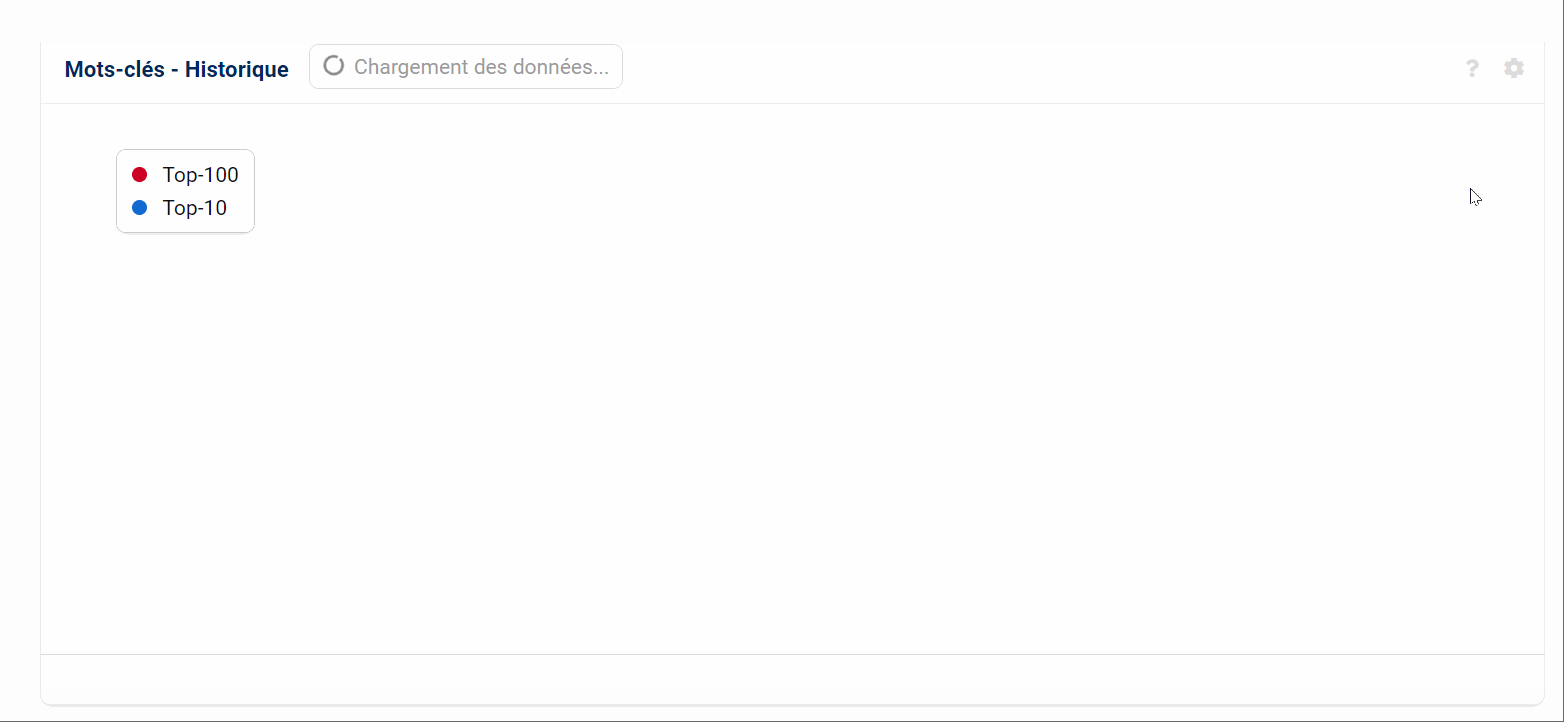
Les données actualisées quotidiennement ont l’avantage d’être très fraîches. Les changements sont visibles immédiatement et sont utiles pour analyser les mises à jour des algorithmes, les migrations et autres changements immédiats. Ils sont également statistiquement comparables dans le temps, puisque chaque pays et chaque appareil compte toujours un million de mots-clés.
L’inconvénient des données mises à jour quotidiennement est qu’il n’y a « que » (précisément) un million de mots-clés. En particulier pour les petits domaines de niche, cet ensemble de mots clés ne couvre pas toujours tous les cas particuliers, les orthographes et les termes à longue queue. Il en va de même pour l’analyse des répertoires individuels ou même des URL du domaine : sur la base d’un million de mots-clés, la base de données peut devenir un peu trop éparse.
C’est l’avantage de la base de données élargies, qui est maintenant utilisée comme standard : par exemple, en France, les analyses ne sont plus basées sur un million de mots-clés, mais sur plus de 51 millions. Une liste actualisée des tailles des bases de données pour tous les pays se trouve sur cette page.
Un inconvénient des données étendues est la fréquence de mise à jour : bien que tous les mots-clés « importants » soient mis à jour quotidiennement, les mots-clés à longue traîne ou rarement recherchés ne sont mis à jour que mensuellement. Par conséquent, les changements dans les données étendues peuvent ne devenir apparents qu’après quelques semaines.
Enfin, nous élargirons régulièrement les bases de données étendues des pays où nous sommes présents : cela entraînera une augmentation dans les tableaux qui ne correspond pas au statu quo réel. Ces expansions seront donc communiquées et signalées par des pins.